반응형
PostgreSQL 에서 숫자나 날짜, 시간 데이터를 생성하는 방법입니다.
generate_series(시작, 종료, [단계 혹은 인터벌])
을 이용하여 간단하게 데이터를 출력해 줄 수 있습니다.
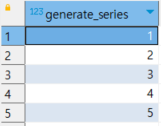
select * from generate_series(1, 5);
select * from generate_series(1, 5, 1);위의 쿼리를 실행하면 아래와 같은 결과를 출력합니다.
select * from generate_series(-4, 3);음수도 생성합니다.

select * from generate_series(-4, 3, -1);하지만 위와 같이 숫자가 커지는 데 단계를 음수로 지정할 경우 아무런 데이터도 반환되지 않습니다.
반대로 시작보다 종료인 수가 작은 데 단계를 양수로 지정하거나 지정하지 않을 경우에도 아무런 데이터도 반환되지 않습니다.
select
current_date + s.a date
from generate_series(0, 14,7) as s(a)위와 같이 생성한 데이터를 이용해 날짜 데이터도 생성하는데 활용 가능합니다.
실행결과 :

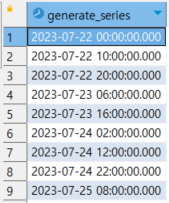
select * from
generate_series('2023-07-22 00:00'::timestamp, '2023-07-25 08:00'::timestamp, '10 hours');
실행결과 :
반응형
'DEV > SQL' 카테고리의 다른 글
| [PostgreSql] 포스트그리 SQL 여러 컬럼 중 최대값, 최소값 구하기 (GREATEST, LEAST) (0) | 2023.07.22 |
|---|---|
| [PostgreSQL] WITH 구문 사용하기 (공통 테이블 방식 : CTE) (0) | 2023.07.21 |
| [PostgreSQL] INSERT, UPDATE, DELETE 실행 결과 조회 (RETURNING) (0) | 2023.07.19 |
| MySql(MariaDB) / Oracle 에서 ROLLUP 사용하기 (0) | 2023.07.07 |
| PostgreSQL Null값 치환 함수 COALESCE (Feat. Oracle NVL) (0) | 2023.07.06 |






